7 教師無し学習
7.1 教師無し学習とは?
教師無し学習にはクラスタリング(グループ分け)と次元削減があります。このうち、クラスタリングはデータの特徴量を解析し、いくつかのグループ(クラスタ)に分けるものです。クラスタ分析ともいいます。
教師無し学習は、 ・顧客のグループ分け ・利用傾向の分類 ・異常データの発見 など、 「答えが分からない状態」からヒントを得るために使われます。
例えば、あやめのデータを使い、クラスタ分析してみましょう。 ファイル cluster.ipynb に以下を記述します。 教師無し学習では今回は正解ラベルを使用しませんのであらかじめ Name を削除しておきます。
import pandas as pd
df = pd.read_csv("iris.csv")
df.drop("Name", axis=1)
df.head()
教師無し学習に使用するアルゴリズムはK平均法が多く使われます。まずいくつのクラスタに分けるかを定めます。例えば3つに分けるとすると、3つのデータをランダムに選びます。これを代表点と呼びます。そのほかのデータは最も近い代表点に所属すると判定します。
その後、クラスタ内の中心となる点を新たな代表点にします。代表点が変化したので再度全てのデータをどの代表点に属するかを判断します。これを代表点が変化しなくなるまで繰り返します。
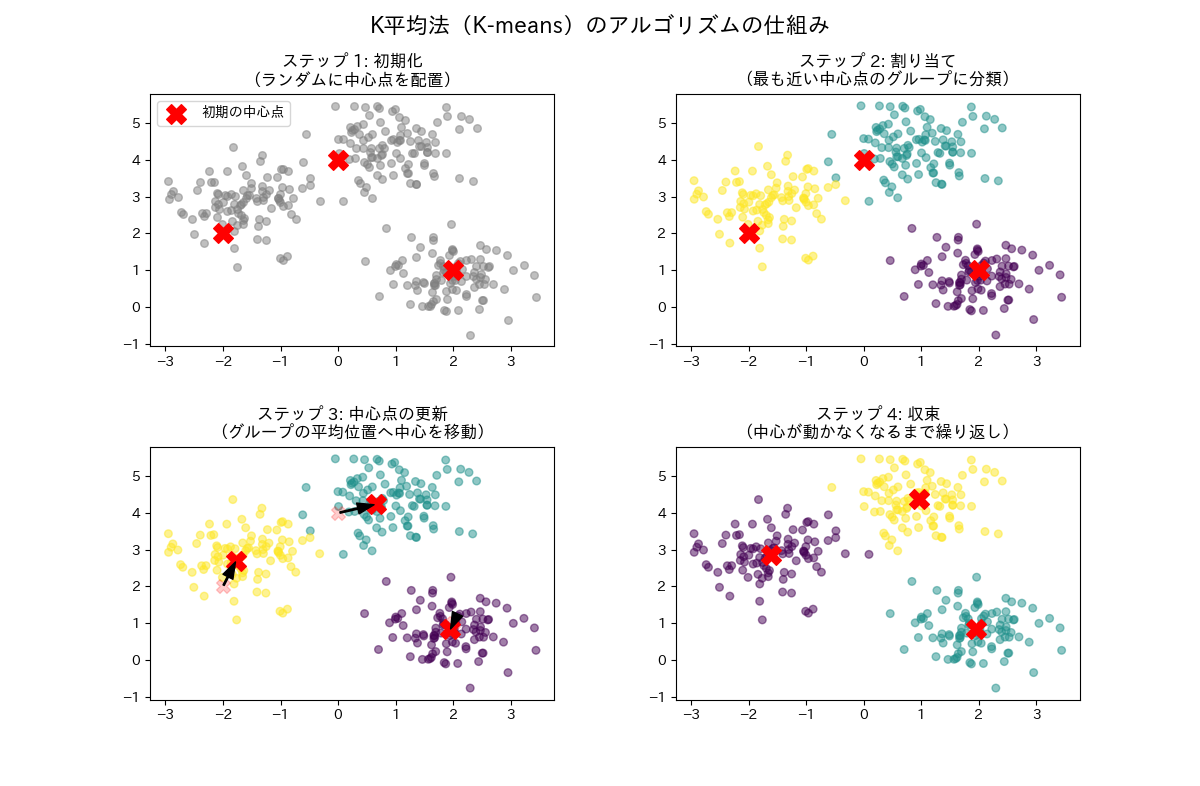
scikit-learnではいくつのクラスタに分けるかを指定するだけです。
# K平均法
from sklearn.cluster import KMeans
# 3つに分類
model = KMeans(n_clusters=3, n_init='auto',random_state=0)
model.fit_predict(df)
7.2 クラスターの特徴を調べる
教師なし学習には正解はありません。あくまで機械的にグループ分けを行っただけですので、それが妥当かどうかは人間が判断する必要があります。
そのため、各クラスタの特徴を調べてみます。 クラスタに分けた結果をcluster列に入れます。
df["cluster"] = model.fit_predict(df)
df
クラスタごとの各列の平均値を見てみましょう。
# cluseterごとの平均値
df.groupby("cluster").mean()
クラスタごとの平均をヒートマップで見てみましょう。
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(font=["Meiryo"])
dfm = df.groupby("cluster").mean()
sns.heatmap(dfm, annot=True, cmap="Oranges")
plt.show()
7.3 いくつのクラスタに分けるか
いくつのクラスタに分けたら良いかはエルボー法がよく使われます。 これはクラスタ内誤差平方和(SSE)を元に行います。クラスタ内誤差平方和は、データと代表点との差を二乗し合計したものです。この数値はクラスタ数を多くすると低下していき、最も小さくなるのはクラスタ数=データ数になったときです。
クラスタ数を次第に大きくしながら、SSEを確認します。SSEは次第に小さくなりますが、ある地点であまり減少しなくなります。そこが最適のクラスタ数と判断できます。

あやめのデータで試してみます。結果をデータフレーム dfs に格納します。2から10までクラスター数を増やしていき、その結果のクラスタ内誤差平方和を model.inertia_ で取得し、DataFrameに入れます。
from sklearn.cluster import KMeans
sse = []
for i in range(2,10): # クラスタ数 2~10
model = KMeans(n_clusters=i, n_init='auto', random_state=0)
model.fit_predict(df)
sse.append(model.inertia_) # リストに追加
df_sse = pd.DataFrame(sse, index=range(2, 10), columns=["SSE"])
df_sse
グラフを表示します。
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(font=["Meiryo"])
df_sse.plot()
plt.title("エルボー法")
plt.show()
3付近で減少が緩やかになるため、クラスタ数は3が妥当だと判断できます。