Python 機械学習 アルゴリズム
アルゴリズムの決定
教師有り:分類
決定木
条件を見つけ決定木を作り分類する。最初はランダムに条件を試す。
引数
- max_depth 決定木の深さ(何段階まで条件を判定するか)例:2
- random_state 乱数の種。整数を指定し固定させ再現性を高める。
from sklearn import tree model = tree.DecisionTreeClassifier(max_depth=3, random_state=0)
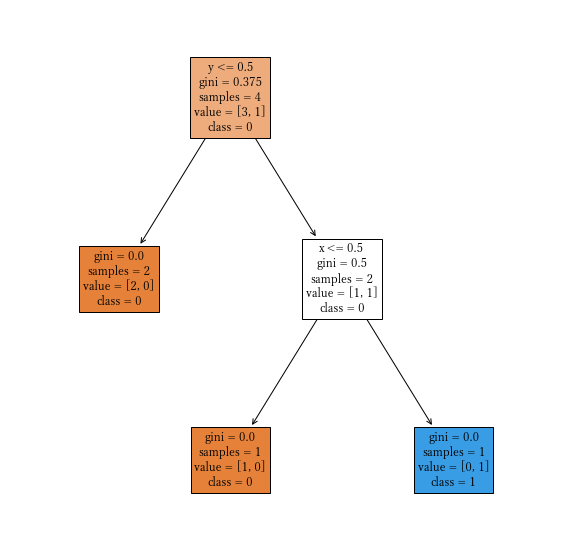
決定木の可視化
tree.plot_tree(model, feature_names=特徴量の列名のリスト,class_names=ラベルの値のリスト,
filled=True, fontsize=12)
import matplotlib.pyplot as plt
plt.subplots(figsize=(16, 12))
tree.plot_tree(model, feature_names=x_train.columns, class_names=y_train.unique(),
filled=True, fontsize=12)
特徴量の重要度表示
model.feature_importances_ で分かるのでそれに列名(x_train.columns)を付けて表示
pd.Series(model.feature_importances_, x_train.columns)
ロジスティック回帰
回帰分析の手法で分類を行う。
引数
- random_state 乱数の種。整数を指定し固定させ再現性を高める。
- C 誤分類のペナルティ(デフォルト1)
from sklearn.linear_model import LogisticRegression model = LogisticRegression(random_state=0)
ランダムフォレスト
決定木をランダムに多数作成し、その多数決で決定する。
引数
- n_estimators 決定木の数。既定値:100
- max_depth 決定木の深さ(何段階まで条件を判定するか)例:2
- random_state 乱数の種。整数を指定し固定させ再現性を高める。
from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier(n_estimators=200,max_depth=3,random_state=0)
# 特徴量の重要度表示 pd.Series(model.feature_importances_,["列名1", "列名2", "列名3"])
XGBoost
勾配ブースティング。
決定木を多数作成し、その予測合計値で決定する。ただし、決定木は前の決定木を元に進化させる。
※教師データは数値であることが必要。
インストール
pip install xgboost
引数
- max_depth 決定木の深さ(何段階まで条件を判定するか)規定値:6
- learning_rate 学習率パラメータ(大きいほど過学習) 規定値:0.3
- gamma 損失減少の下限 規定値:0
from xgboost import XGBClassifier model = XGBClassifier() model.fit(train_x, train_y) model.score(test_x, test_y)
# 特徴量の重要度表示 pd.Series(model.feature_importances_,["列名1", "列名2", "列名3"])
ニューラルネットワーク
引数
- max_iter 反復回数 規定値:200
- hidden_layer_sizes 隠れ層の数 規定値:100
- random_state 乱数の種。整数を指定し固定させ再現性を高める。
from sklearn.neural_network import MLPClassifier model = MLPClassifier(hidden_layer_sizes=(100,), random_state=0, max_iter=1000) model.fit(train_x, train_y) model.score(test_x, test_y)
教師有り:回帰分析
線形回帰
予測用の直線を引く。元データの値が1つの場合には単回帰分析という。
この場合、次のような式になる:係数×値1+定数
値が複数の場合、重回帰分析という。このときには次の式になる。
係数1×値1+係数2×値2+係数3×値3+・・+定数 で表される
from sklearn.linear_model import LinearRegression model = LinearRegression()
係数と定数の表示
- model.coef_ 係数のリスト。大きい方が予測に影響があることが分かる。
- model.intercept_ 定数
# 係数を列名とともに表示 tmp = pd.DataFrame(model.coef_) tmp.index = ["列名1","列名2","列名3"] tmp
リッジ回帰
重回帰分析のうち、1つのデータが重要な場合に使用。
係数の範囲を絞ることで過学習が置きにくい。
- alpha 過学習を防ぐ数。
from sklearn.linear_model import Ridge model = Ridge(alpha=0.1)
ラッソ回帰
予測に役立たない係数を0にする。1つのデータが重要な場合に使用。
- alpha 過学習を防ぐ数。
from sklearn.linear_model import Lasso model = Lasso(alpha=10)
教師無し:分類
K平均法
代表点を分類する数だけ決め、そこからの平均距離が最も近くなるようにする。
最初にランダムに代表点を決め、そこから近いものに分類し、中央点を出す。そこを新たな代表点とし計算する。これを繰り返す。
引数
- n_clusters 分類する数 例:3
- random_state 乱数の種。整数を指定し固定させ再現性を高める。
# K平均法 from sklearn.cluster import KMeans model = KMeans(n_clusters=3,random_state=0) # 3つに分類