Python 機械学習
機械学習 前処理 ディープラーニング LLM機械学習とは
例えば、犬と猫の画像の判別はその違いを人間がプログラムとして指示するのは難しい。
機械学習では人間の指示では無く、プログラム自身が大量のデータを元に学習し、法則を見つける(アルゴリズムを構築する)。学習の方法には教師あり学習と教師なし学習があり、あらかじめ答えのあるデータを元にする学習が教師あり学習。教師なし学習はデータから関連性があるものを自動的に分類する。
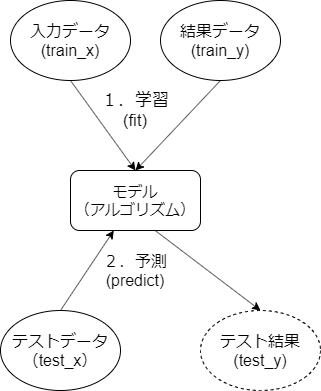
機械学習の手順
- データを用意する。データは学習データと教師データ(答えのデータ)から成る
- データに不正な値は存在しない部分(欠損値)がある場合には、正しく処理できるように前処理を行う。
- データを元に機械学習を行い、モデルを構築する
- テストデータをモデルを使って予測し、結果を評価する
- 本データで予測する
Scikit-learn環境構築
機械学習ライブラリである「Scikit-learn」の環境を構築する。
pip install scikit-learn
Scikit-learn And演算の学習
XからYを求める。And演算で言えば、Xが[0,0]のとき、Yは0になる。
学習用データには x_train、y_trainのような名前を付ける。
Scikit-learnで学習をさせるには、アルゴリズムを選択しモデルを作り、fit関数にデータと答えを入れることで学習できる。
学習後に予測するにはモデルのpredict関数を使う。
# And演算の学習 # 学習用データ問題 x_train = [[0,0], [1,0], [0,1], [1,1]] # 学習用データ答え(教師データ) y_train = [0, 0, 0, 1] # 学習アルゴリズムを指定 from sklearn.svm import LinearSVC model = LinearSVC() # 学習 model.fit(x_train, y_train) # 予測 model.predict([[1,1]]) # 1,1は1、0,1は0、0,0,は0
1つ1つ予測するのでは無くまとめて予測し、正解率を出す。 正解率は model.score(問題,答え) で出せる。
# テストデータ x_test = [[0,0], [1,0], [0,1], [1,1]] # テスト答え y_test = [0, 0, 0, 1] # 結果の正解率を表示 model.score(x_test, y_test)
教師有り学習:分類
サンプルデータのダウンロード
あやめ(Iris)のデータをダウンロードする。
以下のrawを右クリックし、iris.csvでダウンロード。
https://github.com/pandas-dev/pandas/blob/master/doc/data/iris.data
- SepalLength 花がくの長さ
- SepalWidth 花がくの幅
- PetalLength 花びらの長さ
- PetalWidth 花びらの幅
- Name 種類
読み込み
import pandas as pd
df = pd.read_csv("iris.csv")
df
学習用データと教師データの取得
# 学習データ x = df[["SepalLength", "SepalWidth", "PetalLength", "PetalWidth"]] # 教師データ y = df["Name"]
機械学習によるモデルの構築
今回は決定木モデルを利用
from sklearn import tree # モデルの構築 model = tree.DecisionTreeClassifier(random_state=0) # 学習する model.fit(x, y)
モデルによる予測
model.predict([[5.5, 3.8, 1.9, 1.2]])
機械学習の検証
読み込んだデータをあらかじめ、学習用と予測用に分ける。
train_test_splitを使うと、割合を指定して分けることが出来る。test_sizeにテスト用データの割合を指定する。
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2)
# 学習する model.fit(x_train, y_train) # 結果の検証 model.score(x_test,y_test)
モデルの保存
作成したモデルをpickeを使い、ファイルに保存する。
# model保存
import pickle
with open('iris.pkl','wb') as f:
pickle.dump(model,f)
別のプログラムでpickeでモデルを読み込み予測を行ってみる。
# modelに読み込み
import pickle
with open('iris.pkl','rb') as f:
model = pickle.load(f)
# 予測
pred = model.predict([[5.5, 3.8, 1.9, 1.2]])
print(pred)
その他の例
教師有り学習:回帰分析
時系列データなど連続するデータは直線のグラフを想定して予測が出来る。
標準化
回帰分析を行う前にデータの大小の差が大きい場合には標準化を行い、数字の重みの差を無くしておく。
from sklearn.preprocessing import StandardScaler sc_model = StandardScaler() x_train = sc_model.fit_transform(x_train)
パイプライン
パイプラインを使うと、標準化後の回帰分析を簡単に行うことが出来る。
# パイプラインの構築 from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LinearRegression from sklearn.pipeline import make_pipeline pipeline = make_pipeline(StandardScaler(), LinearRegression()) # 学習 pipeline.fit(x_train, y_train) # 評価 pipeline.score(x_test, y_test)
係数を表示するにはpipeline.named_stepsでモデル名を小文字で指定し、モデルを取得してから表示します。
model = pipeline.named_steps["linearregression"] pd.DataFrame(model.coef_, index=x_train.columns, columns=["係数"])
多項式回帰
単純な線形回帰では捉えられない非線形な関係をモデル化できるように多項式の回帰を行う。y = A+ + B * x + C * X^2 のような計算式で計算を行う。degreeは多項式の次数を表し、2 の場合、2乗(放物線)、3の場合、三乗(三次曲線)となる。
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
pipeline = Pipeline([
('poly', PolynomialFeatures(degree=2)),
('linear', LinearRegression())
])
# 学習する
pipeline.fit(x_train, y_train)
教師無し学習:分類
3つに分類する
import pandas as pd
df = pd.read_csv("iris.csv")
# 学習データ
x = df[["SepalLength", "SepalWidth", "PetalLength", "PetalWidth"]]
# K平均法
from sklearn.cluster import KMeans
model = KMeans(n_clusters=3) # 3つに分類
pred = model.fit_predict(x)
print(pred)