Python 機械学習による気温予測
回帰分析
数値のデータ予測。単一数値からの予測を単回帰分析(例:昨日の気温から今日の気温を予測)、複数の数値からの予測を重回帰分析(例:過去7日分の気温から今日の気温を予測)という。
気温データのダウンロード
https://www.data.jma.go.jp/gmd/risk/obsdl/index.php
項目を選ぶ:「データの種類」は「日別値」、「項目」は「日最高気温」
期間を選ぶ:10年間分1/1~12/31
表示オプションを選ぶ:「ダウンロードCSVファイルのデータ仕様」で「すべて数値で格納」、「年月日などに分けて格納」
ダウンロードしたデータをテキストエディタで開き不要部分を削除。1行目を「年,月,日,最高気温,品質,均質」にし、UTF-8で保存する。
データの加工
読み込み
import pandas as pd
df = pd.read_csv("data.csv")
過去データを行に入れる
# 1日前~7日前 までの列を作成、気温を入れる
df2 = pd.concat([df,
df["最高気温"].shift(1),
df["最高気温"].shift(2),
df["最高気温"].shift(3),
df["最高気温"].shift(4),
df["最高気温"].shift(5),
df["最高気温"].shift(6),
df["最高気温"].shift(7)], axis=1
)
df2 = df2.dropna()
df2.columns = ["年","月","日","最高気温","1日前","2日前","3日前","4日前","5日前","6日前","7日前"]
df2
訓練データとテストデータの振り分け
最後の1年をテストデータ、それ意外を訓練データとする。
x = df2[["1日前","2日前","3日前","4日前","5日前","6日前","7日前"]] y = df2["最高気温"] # 訓練データ x_train = x[:-365].reset_index(drop=True) # 後ろの365個を除く y_train = y[:-365].reset_index(drop=True) # テストデータ x_test = x[-365:].reset_index(drop=True) # 後ろの365個のみ y_test = y[-365:].reset_index(drop=True)
機械学習
機械学習によるモデルの構築
LinearRegression(重回帰分析)によるモデルの構築
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(x_train, y_train) # 学習 pre = model.predict(x_test) # 予測
検証
グラフ
import matplotlib.pyplot as plt plt.figure() plt.plot(y_test, c='r') # 実際の気温を赤 plt.plot(pre, c='b') # 予測の気温を青 plt.show()
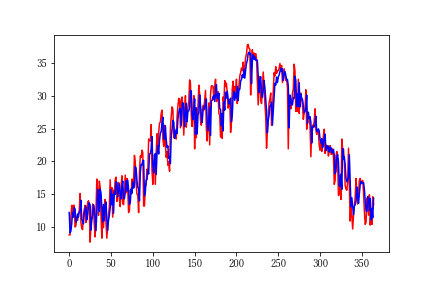
平均絶対誤差
どれぐらい誤差があったかの平均を計算
from sklearn.metrics import mean_absolute_error mean_absolute_error(y_pred=pre,y_true=y_test)
決定係数
一般に0.8以上ならよいモデル
model.score(x_test,y_test)
予測
pred = pd.DataFrame() pred["1日前"] = [2.2] pred["2日前"] = [3.4] pred["3日前"] = [6.1] pred["4日前"] = [10.0] pred["5日前"] = [12.1] pred["6日前"] = [9.4] pred["7日前"] = [6.9] pre = model.predict(pred) # 予測 pre
係数の確認
model.coef_ で各列の係数(及ぼす影響度)が分かる。
keisu = pd.DataFrame(model.coef_) keisu.index = ["1日前","2日前","3日前","4日前","5日前","6日前","7日前"] keisu