Python データ分析 グラフ
グラフの準備
折れ線グラフ
pandas内のmatplotlibを利用し、グラフを表示する。
import pandas as pd
df = pd.read_csv("kd2018.csv", index_col = '回')
df.plot()
seaborn利用
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(font=["Meiryo"])
df = pd.read_csv("kd2018.csv")
df.plot()
plt.show()
表示するデータを指定
df.plot(y="総数")
#複数指定 df.plot(y=["男性","女性"])
オプション
タイトル
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(font=["Meiryo"])
df.plot(y="総数")
plt.title("参加人数")
ラベル
df.plot(y="総数")
plt.title("参加人数")
plt.xlabel('開催回')
plt.ylabel('人数')
フォントサイズ
df.plot(y="総数")
plt.title("参加人数",fontsize=20)
plt.xlabel('開催回',fontsize=14)
plt.ylabel('人数',fontsize=10)
サイズ
df.plot(y="総数",figsize=(10,6))
縦軸の範囲
ylim=(最小値, 最大値)df.plot(y=["男性","女性"], ylim=(10,100))
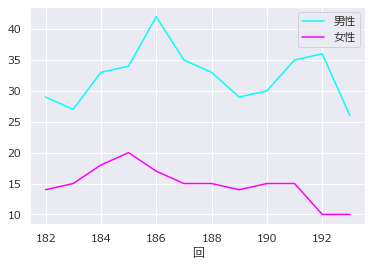
色
colorに色の名前、または16進色コード(#ff0000など)のリストを指定する
df.plot(y=["男性","女性"],color=['blue','red'])
またはcolomapを指定する
df.plot(y=["男性","女性"],colormap='cool')
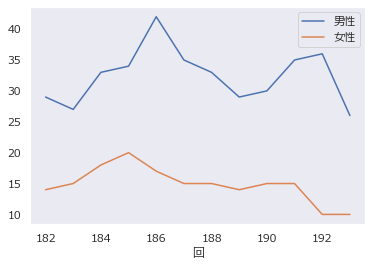
グリッド
df.plot(y=["男性","女性"],grid=False)
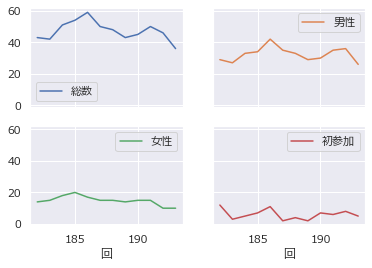
複数グラフ
df.plot(subplots=True,layout=(2,2),sharey=True)
画像の保存
ax = df.plot()
fig = ax.get_figure()
fig.savefig('graph.png')
※Jupyterから直接保存するにはShift+右クリックして、[名前を付けて画像を保存]
subplotsを指定した場合、ax[0][0].get_figure() で取得
指数表示の解除
大きい数字の場合、目盛りに指数で表示されることがある。例えば1e7と目盛りに付いた場合、単位が10の7乗として表示される。
これを解除するには以下のようにする(y軸の場合)。
ax = df.plot(y="回") ax.ticklabel_format(style="plain", axis = "y")
描画
点の描画
df.plot(y=["男性","女性"]) x = 190 y = 30 plt.plot(x, y, c="r", marker="X", markersize=15)
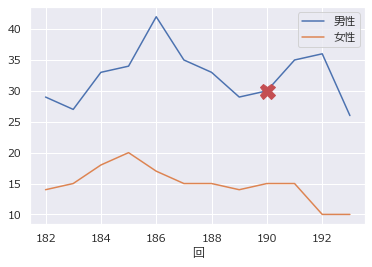
マーカーの種類
marker="." # 点 marker="o" # 円 marker="s" # 正方形 marker="^" # 上向き三角形 marker="v" # 下向き三角形 marker="<" # 左向き三角形 marker=">" # 右向き三角形 marker="X" # ×
線を描画
# 縦線 plt.axvline(x, c="r", linestyle="--") # 横線 plt.axhline(y, c="r", linestyle="--")
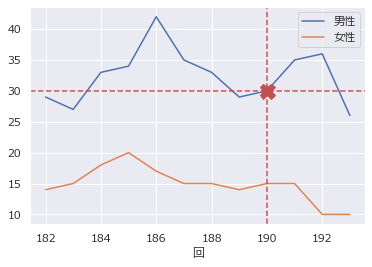
線の種類
linestyle="-" # 実線 (solid) linestyle="--" # 破線 (dashed) linestyle=":" # 点線 (dotted)
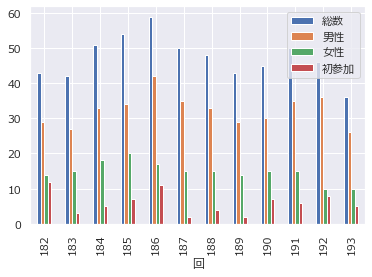
棒グラフ
df.plot.bar()
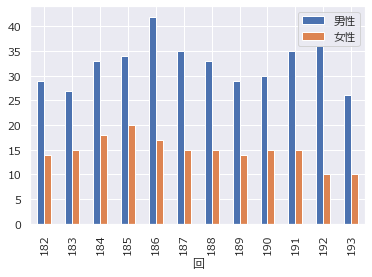
# 男性と女性 df.plot.bar(y=["男性","女性"])
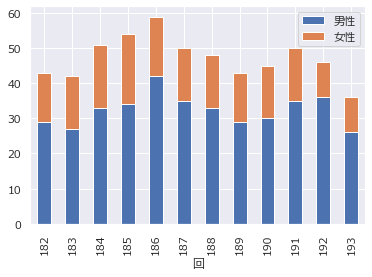
# 積み上げ棒グラフ df.plot.bar(y=["男性","女性"], stacked=True)
# 水平棒グラフ df.plot.barh(y=["男性","女性"])
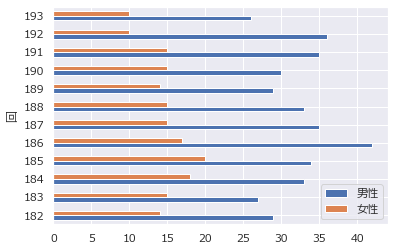
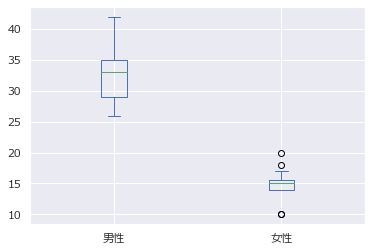
箱ひげ図
箱の中央が中央値(第二四分位点)、箱の範囲が上下が25%の枠(第一四分位点、第三四分位点)。箱の外の上が最大値、下が最小値。
箱の長さの1.5倍以上箱から離れている値は外れ値として最大値・最小値の対象外(○で表示)
df[["男性","女性"]].plot.box()
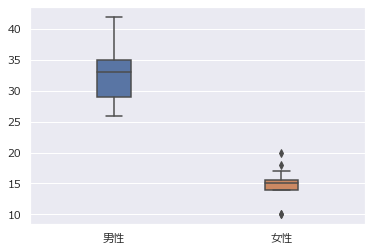
seabornを使用した箱ひげ図
sns.boxplot(data = df[["男性","女性"]], width=0.2)
箱の大きさ=第三四分位点-第一四分位点
箱の下辺=第一四分位点
箱の上辺=第三四分位点
# 第一四分位点 q1= df["女性"].quantile(0.25) # 第三四分位点 q3= df["女性"].quantile(0.75) # 箱の範囲 iqr=q3-q1 # 下限 min = q1 - iqr*1.5 # 上限 max = q3 + iqr*1.5 # 上限以上 df[df["女性"]>= max]
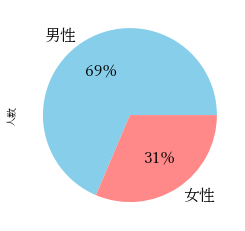
円グラフ
pie()関数にstartangleとcounterclockを指定し、日本で一般的には上から時計回りに表示した場合
s = df[["男性","女性"]].sum() # 合計 d = pd.DataFrame(s, columns=["人数"]) d["人数"].plot.pie(startangle=90, counterclock=False)
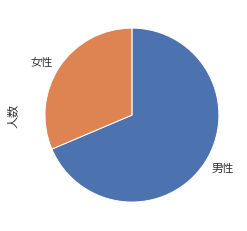
# 割合表示形式、フォント、色
d["人数"].plot.pie(autopct = "%1.0f%%",textprops = {"fontsize":"16"},colors = ["skyblue","#ff8888"])
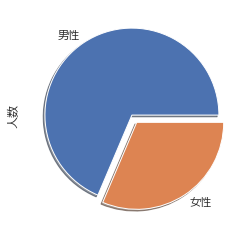
# 切り離し、陰 d["人数"].plot.pie(explode = (0, 0.1),shadow = True)
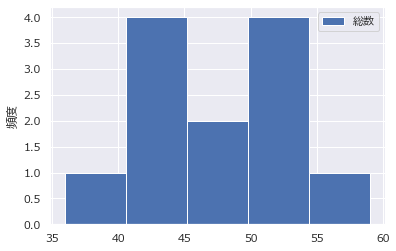
ヒストグラム
頻度のグラフ。データの散らばり方が分かる。binsで何区間に分割するかを指定する。
区間数は目安としては総数の平方根程度にする。
ax = df.plot.hist(y="総数",bins=5)
ax.set_ylabel('頻度') # ラベル表示
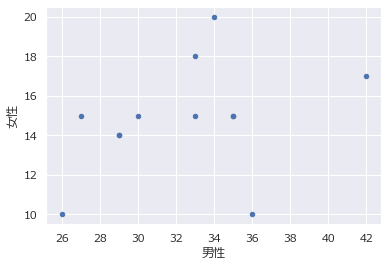
散布図
2つのデータの関係を示す図。右肩上がりだと正の相関、右肩下がりだと負の相関がある。
df.plot.scatter(x="男性",y="女性",c='b')
2つのデータの関係を示す図。右肩上がりだと正の相関、右肩下がりだと負の相関がある。
df.plot.scatter(x="男性",y="女性",c='b')
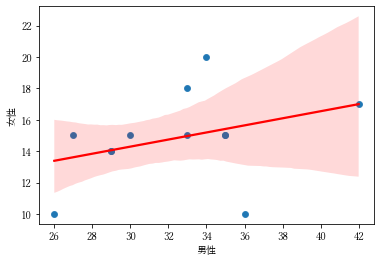
回帰分析
2つの量から回帰直線を引くことが出来る。
df.plot.scatter(x="男性",y="女性",c='b')
sns.regplot(data=df, x="男性", y="女性", line_kws={"color":"red"})
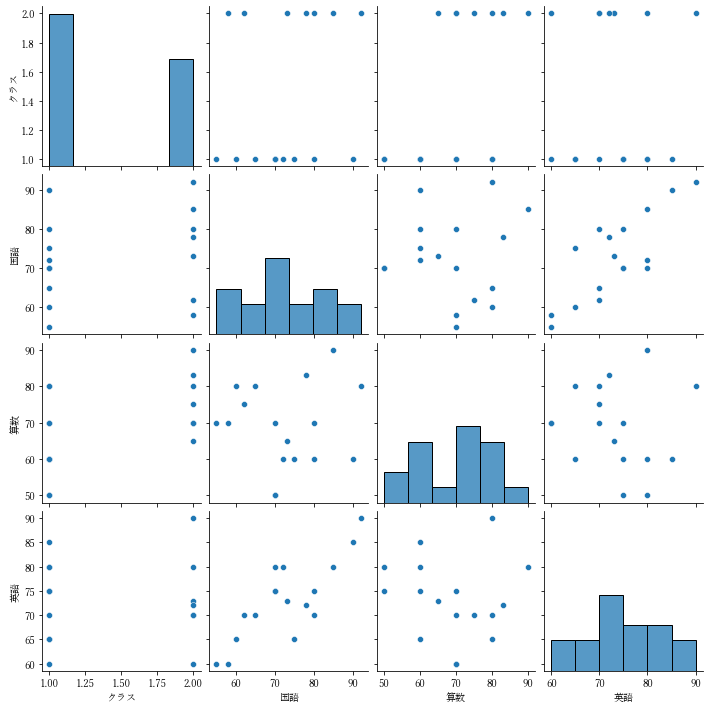
総当たりの散布図
sns.pairplot(data=df)
sns.pairplot(data=df, hue="列") # 列ごと
import pandas as pd
df = pd.read_csv("seiseki2.csv")
sns.pairplot(data=df)
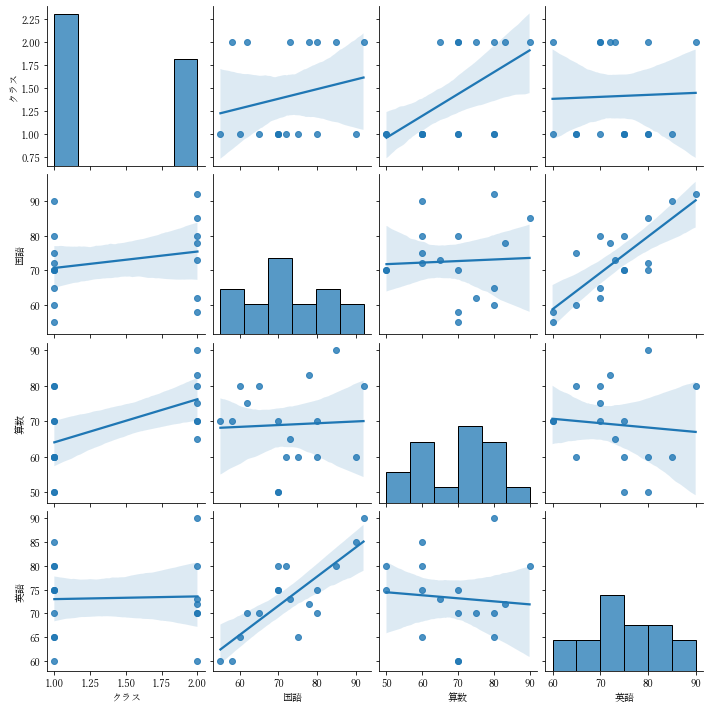
回帰分析付き
import pandas as pd
df = pd.read_csv("seiseki.csv")
sns.pairplot(data=df, kind="reg")
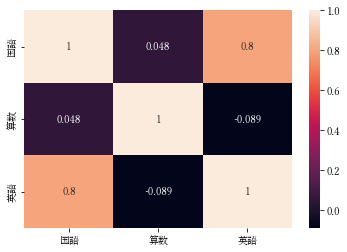
ヒートマップ
相関の強さを熱で表現
df = pd.read_csv("seiseki.csv")
sns.heatmap(df[["国語","算数","英語"]].corr(), annot=True)
スタイル
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(font=["Meiryo"],style='whitegrid')
df = pd.read_csv("kd2018.csv")
df.plot()
使用可能なスタイル
dark,darkgrid,white,whitegrid,ticks