Python 自然言語処理
自然言語処理とは?
自然言語とは、人間が通常会話で使用する言語(反対語:人工言語=プログラミング言語など)。自然言語処理とはそのような言語を処理する技術。
spaCyとGiNZA
spaCyは多言語対応の自然言語処理ライブラリ。GiNZAはspaCyから利用可能な日本語の自然言語処理。リクルートと国立国語研究所が共同で開発。
インストール
pip install ja-ginza
オブジェクトの生成
spacy.Loadでnlpオブジェクト(Languageクラス)を生成し、それに文章を与えることで、Docクラスを生成する。
import spacy
nlp = spacy.load('ja_ginza')
text = '今日は晴れです。明日は雨ですか? いいえ曇りです。'
doc = nlp(text)
文章の分割
docクラスのsentsは文章のリストとなる。以下は一文ずつ区切って表示される。
for s in doc.sents:
print(s.text)
上の例の場合、以下のように表示される。
今日は晴れです。 明日は雨ですか? いいえ曇りです。
単語の分割
Docクラスをfor文の対象にすることでtoken(単語)を得ることが出来る。
text = '藤井聡太は将棋が好きです。' doc = nlp(text) for token in doc: print(token.text, token.pos_, token.tag_) #単語、品詞(英語)、品詞(日本語)
品詞
| ADJ | 形容詞(adjective) |
| ADP | 設置詞(adposition) |
| ADV | 副詞(adverb) |
| AUX | 助動詞(auxiliary) |
| CONJ | 接続詞(conjunction) |
| CCONJ | 等位接続詞(coordinating conjunction) |
| DET | 限定詞(determiner) |
| INTJ | 間投詞、感嘆詞(interjection) |
| NOUN | 名詞(noun) |
| NUM | 数詞(numeral) |
| PART | 助詞(particle) |
| PRON | 代名詞(pronoun) |
| PROPN | 固有名詞(proper noun) |
| PUNCT | 句読点(punctuation) |
| SCONJ | 従属接続詞(subordinating conjunction) |
| SYM | シンボル(symbol) |
| VERB | 動詞(verb) |
| X | 他(other) |
| SPACE | 空白(space) |
依存関係の可視化
単語の品詞とその依存関係を表示する。
from spacy import displacy displacy.render(doc)
エンティティと名詞句
エンティティ=現実世界のオブジェクト。以下でテキスト中に埋め込んで可視化。
from spacy import displacy displacy.render(doc, style="ent")
エンティティを一つ一つ表示するにはdoc.entsをfor文で取り出す。
for ent in doc.ents: print(ent.text, type(ent))
名詞句を一つ一つ表示するにはdoc.noun_chunksをfor文で取り出す。
doc2 = nlp('藤井聡太は偉大な棋士です。')
for chunk in doc2.noun_chunks:
print(chunk.text, type(chunk))
ベクトル化と類似度の計算
文章の意味を数値化するのがベクトル化。ベクトルとは数値の配列。これを比較すると似ているかどうかが分かる。
numpyによるベクトル化
ベクトル化の意味を学習するために、Bag of Words (BoW)によるベクトル化を実装してみる。これは単語の出現数を配列化したものである。
import numpy as np
# 入力テキストのサンプル(単語を区切りやすいように空白区切り)
documents = [
"熊本 の ゆるキャラ は くまモン",
"くまモン は かわいい ゆるキャラ",
"熊本城 は 熊本 の 城"
]
# 3つの文書から全単語を抽出
vocabulary = []
for doc in documents:
words = doc.split() # 各ドキュメントを単語に分割
for word in words:
if word not in vocabulary:
vocabulary.append(word)
# 各文書をベクトル化
def vectorize(doc):
words = doc.split()
vector = np.zeros(len(vocabulary)) # 全単語の数だけ0の要素を持つ配列
for word in words:
if word in vocabulary: # 単語がある
index = vocabulary.index(word)
vector[index] += 1 # カウントアップ
return vector
# 全文書をベクトル化して表示
for doc in documents:
print(f"テキスト: {doc}")
print(f"ベクトル: {vectorize(doc)}\n")
ベクトルを比較し、コサイン類似度を求める。コサイン類似度は-1~1までの値。1に近いほど文章が似ている。
# 全文書をベクトル化し、配列に入れる。
vectors = np.array([vectorize(doc) for doc in documents])
# コサイン類似度を計算する関数 (numpyを使用)
def cosine_similarity(vec1, vec2):
if np.linalg.norm(vec1) == 0 or np.linalg.norm(vec2) == 0:
return 0.0
return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
# 各ドキュメント間のコサイン類似度を計算
for i in range(len(vectors)):
for j in range(i + 1, len(vectors)):
similarity = cosine_similarity(vectors[i], vectors[j])
print(f"コサイン類似度 {i+1} と {j+1}: {similarity:.4f}")
spaCyによるベクトル化
doc1 = nlp('ロアッソ熊本はJリーグに所属しています')
print(doc1.vector)
Docクラスのsimilarityにて、文章をベクトル化した場合のコサイン類似度を求める。コサイン類似度は-1~1までの値。1に近いほど文章が似ている。
doc1 = nlp('ロアッソ熊本はJリーグに所属しています')
doc2 = nlp('ロアッソ熊本はサッカーチームです')
doc3 = nlp('熊本城は加藤清正が築城しました')
print(doc1.similarity(doc2))
print(doc1.similarity(doc3))
print(doc2.similarity(doc3))
nlplotの利用
nlplotは自然言語処理において、さまざまな可視化ができるライブラリ。
準備
pip install nlplot nbformat plotly
※対象となるファイルを用意。下の例では「走れメロス」を青空文庫よりダウンロード。
コード
まず、ファイルを1行ずつ読み込み、行毎に単語を分割する。それをリストに入れる。
import spacy
# ファイル読み込み
with open("hashire_merosu.txt", 'r', encoding='utf-8') as file:
lines = file.readlines()
# 単語の取得
nlp = spacy.load("ja_ginza")
include_pos = ('NOUN', 'VERB', 'ADJ') # 名刺、動詞、副詞を対象(固有名詞対象は PROPN も追加)
stopwords = ('する', 'ある', 'ない', 'いう', 'もの', 'こと', 'よう', 'なる', 'ほう', 'いる','る','\n\n','\n ') # 対象外
wordlist = []
for text in lines:
doc = nlp(text)
words = [token.lemma_ for token in doc
if token.pos_ in include_pos and token.lemma_ not in stopwords]
wordlist.append(" ".join(words))
wordlist
できあがったリストをDataFrameに入れる。
import pandas as pd
import numpy as np
df = pd.DataFrame(wordlist, columns = ['text'])
#空白をNaNに置き換え
df['text'].replace('', np.nan, inplace=True)
#Nanを削除 inplace=Trueでdf上書き
df.dropna(subset=['text'], inplace=True)
df[:15]
ユニグラムの作成
頻出上位の単語を示すグラフを表示する。
import nlplot
npt = nlplot.NLPlot(df, target_col='text')
npt.bar_ngram(
title='uni-gram',
xaxis_label='word_count',
yaxis_label='word',
ngram=1,
top_n=50,
)
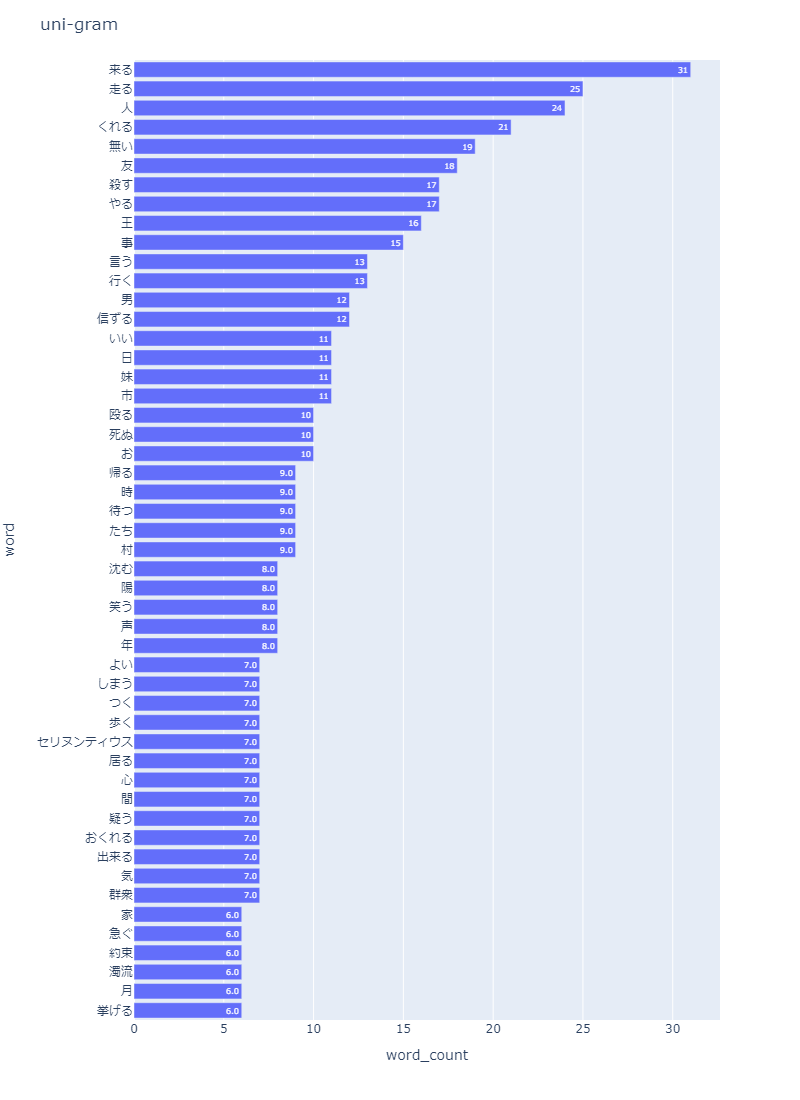
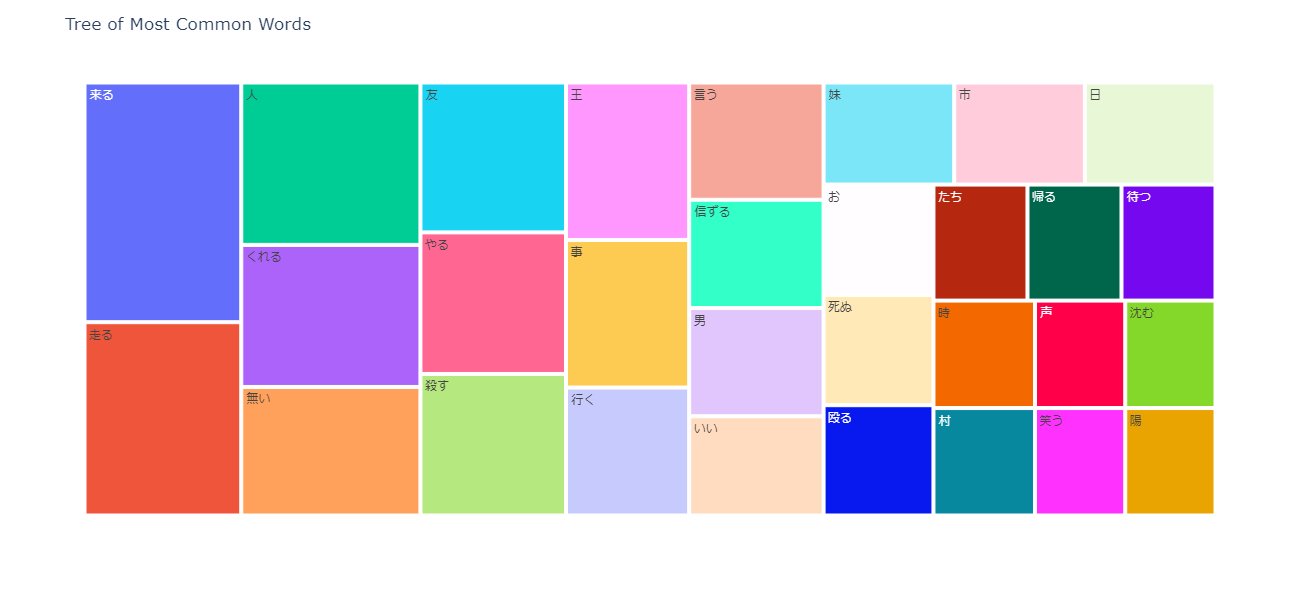
ツリーマップの作成
頻出上位の単語を示すツリーマップを表示する。
npt.treemap( title='Tree of Most Common Words', ngram=1, top_n=30, # stopwords=stopwords, #前処置にて除去しているため適用していない )
単語数の分布
一行にどれぐらいの単語があるかを示すヒストグラムを表示する。
npt.word_distribution(
title='number of words distribution',
xaxis_label='count',
)
共起ネットワーク
単語がどの単語とどれぐらいの絡みがあるかを示すネットワーク図を表示する。
※plotly をインストールしていない場合 pip install plotly
import nlplot npt = nlplot.NLPlot(df, target_col='text') # 共起ネットワーク用のデータフレーム作成。min_edge_frequencyで最低隣接数を指定する。この数が小さいとグラフの表示に時間がかかる npt.build_graph(min_edge_frequency=3) ax = npt.co_network(title="共起ネットワーク") from plotly.offline import iplot iplot(ax)
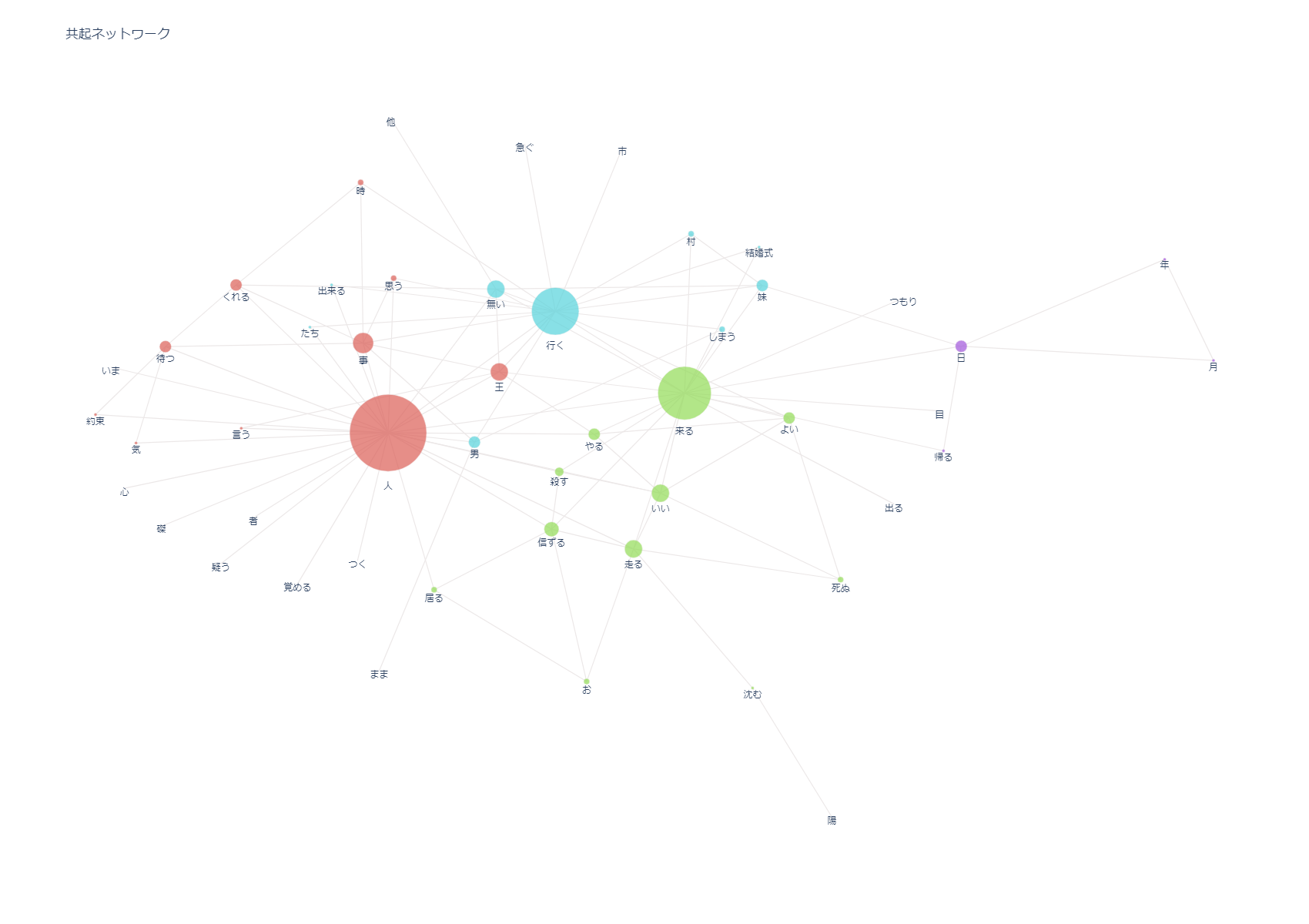
どのようなノードがあり、どのぐらいの単語数と絡みがあるかはnpt.node_df に入っている。
npt.node_df
また、どのノードとどのノードがどれぐらい絡みがあるかはnpt.edge_df に入っている。
npt.edge_df
ワードクラウドの生成
import nlplot
npt = nlplot.NLPlot(df, target_col='text')
wc = npt.wordcloud(
max_words=100,
max_font_size=100,
colormap='tab20_r',
# stopwords=stopwords,
)
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 4))
plt.imshow(wc)
plt.axis("off")
plt.tight_layout(pad=0)
plt.show()

類似度の計算
文章をベクトル化し、類似度をそれぞれ表示してみる。
複数文章の類似度の計算
類似度はコサイン類似度として表示される。コサイン類似度は-1~1で表され、1に近いほど最も似ている。-1に近いほど真逆である。0に近いほど無関係である。
import spacy
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
texts = [
"好きな食べ物はカレーです?",
"熊本に住んでいます",
"今日は晴れです",
"年齢は二十歳です",
"好きなアニメは【推しの子】です",
]
nlp = spacy.load("ja_ginza")
query = input("質問:")
# 質問と全テキストをベクトル化
query_embedding = [nlp(query).vector]
chunk_embeddings = [nlp(t).vector for t in texts]
# コサイン類似度を計算
similarities = cosine_similarity(query_embedding, chunk_embeddings)[0]
# 類似度を表示
print(similarities)
実行例
質問好きなアニメは [0.7768518 0.6222656 0.6632121 0.5997186 0.8742658]
最も類似度が高いものを返す関数を作成
import spacy
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
texts = [
"好きな食べ物はカレーです?",
"熊本に住んでいます",
"今日は晴れです",
"年齢は二十歳です",
"好きなアニメは【推しの子】です",
]
nlp = spacy.load("ja_ginza")
# 最も類似度が高いものを返す関数
def get_top_similar(query, texts):
# 質問と全テキストをベクトル化
query_embedding = [nlp(query).vector]
chunk_embeddings = [nlp(t).vector for t in texts]
# コサイン類似度を計算
similarities = cosine_similarity(query_embedding, chunk_embeddings)[0]
# 類似度が高い1件を取得
index = np.argsort(similarities)[-1]
return texts[index]
query = input('質問:')
similar = get_top_similar(query, texts)
print(similar)